Plugin DSL に移行ながらの気持ちが悪いのは以下の変化。
// 2020-10-13
// build.gradle ( root | Project )
classpath "com.android.tools.build:gradle:4.0.2"
// build.gradle ( module | Module )
apply plugin: 'com.android.application'
// 2022-10-25
// build.gradle ( root | Project )
plugins {
id 'com.android.application' version '7.3.1' apply false
id 'com.android.library' version '7.3.1' apply false
}
// build.gradle ( module | Module )
plugins {
id 'com.android.application'
}

ここに登場する3つの文字列。
com.android.tools.build:gradle
com.android.application
com.android.library
ここらがなんとなくあやふやに使っていたのでよく調べてみます。
■ アプリケーションかライブラリか
root の build.gradle でプラグインのバージョンを指定しておいて、
// 2022-10-25
// build.gradle ( root | Project )
plugins {
id 'com.android.application' version '7.3.1' apply false
id 'com.android.library' version '7.3.1' apply false
}
その子のモジュールの build.gradle で適用する、
// 2022-10-25
// build.gradle ( module | Module )
plugins {
id 'com.android.application'
}
ということです。
👉 Applying external plugins with same version to subprojects - Using Gradle Plugins

そのときに、そのモジュールがアプリケーションかライブラリかで適用するGradleプラグインのIDが変わります。
plugins {
id 'com.android.application'
}
plugins {
id 'com.android.library'
}
👉 Android ライブラリの作成 | Android デベロッパー | Android Developers

■ 'com.android.tools.build:gradle' の記述
Plugin DSL が登場する前は以下のような記述でしたが、
// 2020-10-13
// build.gradle ( root | Project )
classpath "com.android.tools.build:gradle:4.0.2"
// build.gradle ( module | Module )
apply plugin: 'com.android.application'
Plugin DSL では消えてます、"com.android.tools.build:gradle"。
👉 【Plugin DSL】Android Gradle Plugin のバージョンがわからない

ここで、Plugin ID から参照されるリポジトリの内容を見てみます。
Google Maven Repository では、
Plugin Marker Artifacts
Since the plugins {} DSL block only allows for declaring plugins by their globally unique plugin id and version properties, Gradle needs a way to look up the coordinates of the plugin implementation artifact. To do so, Gradle will look for a Plugin Marker Artifact with the coordinates plugin.id:plugin.id.gradle.plugin:plugin.version. This marker needs to have a dependency on the actual plugin implementation. Publishing these markers is automated by the java-gradle-plugin.
プラグインマーカーアーティファクト
plugins {} DSLブロックでは、グローバルにユニークなプラグインIDとバージョンプロパティによってのみプラグインを宣言できるので、Gradleはプラグイン実装アーティファクトの座標を検索する方法が必要です。そのために、Gradleは plugin.id:plugin.id.gradle.plugin:plugin.version という座標を持つプラグインマーカーアーティファクトを探します。このマーカーは、実際のプラグイン実装への依存関係を持つ必要があります。これらのマーカーの発行は、java-gradle-pluginによって自動化されます。
👉 Plugin Marker Artifacts - Using Gradle Plugins

plugin.id:plugin.id.gradle.plugin:plugin.version
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ということなので、
Plugin ID : com.android.application は、
Group Id : com.android.application
Artifact ID : com.android.application.gradle.plugin
で、
Plugin ID : com.android.library は、
Group Id : com.android.library
Artifact ID : com.android.library.gradle.plugin
で、検索します。
Group ID com.android.application
Artifact ID com.android.application.gradle.plugin
Version 8.0.0-alpha06
Gradle Groovy DSL
implementation 'com.android.application:com.android.application.gradle.plugin:8.0.0-alpha06'
Gradle Kotlin DSL
implementation("com.android.application:com.android.application.gradle.plugin:8.0.0-alpha06")
Last Updated Date 10/24/2022
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.android.application</groupId>
<artifactId>com.android.application.gradle.plugin</artifactId>
<version>8.0.0-alpha06</version>
<packaging>pom</packaging>
<description>Gradle plug-in to build Android applications.</description>
<url>https://developer.android.com/studio/build</url>
<name>com.android.tools.build.gradle</name>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>http://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<developers>
<developer>
<name>The Android Open Source Project</name>
</developer>
</developers>
<scm>
<connection>git://android.googlesource.com/platform/tools/base.git</connection>
<url>https://android.googlesource.com/platform/tools/base</url>
</scm>
<dependencies>
<dependency>
<groupId>com.android.tools.build</groupId>
<artifactId>gradle</artifactId>
<version>8.0.0-alpha06</version>
</dependency>
</dependencies>
</project>

Group ID com.android.library
Artifact ID com.android.library.gradle.plugin
Version 8.0.0-alpha06
Gradle Groovy DSL
implementation 'com.android.library:com.android.library.gradle.plugin:8.0.0-alpha06'
Gradle Kotlin DSL
implementation("com.android.library:com.android.library.gradle.plugin:8.0.0-alpha06")
Last Updated Date 10/24/2022
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.android.library</groupId>
<artifactId>com.android.library.gradle.plugin</artifactId>
<version>8.0.0-alpha06</version>
<packaging>pom</packaging>
<description>Gradle plug-in to build Android applications.</description>
<url>https://developer.android.com/studio/build</url>
<name>com.android.tools.build.gradle</name>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>http://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<developers>
<developer>
<name>The Android Open Source Project</name>
</developer>
</developers>
<scm>
<connection>git://android.googlesource.com/platform/tools/base.git</connection>
<url>https://android.googlesource.com/platform/tools/base</url>
</scm>
<dependencies>
<dependency>
<groupId>com.android.tools.build</groupId>
<artifactId>gradle</artifactId>
<version>8.0.0-alpha06</version>
</dependency>
</dependencies>
</project>
👉 com.android.library.com.android.library.gradle.plugin-8.0.0-alpha06 - Google's Maven Repository

それぞれ、同じ
<dependency>
<groupId>com.android.tools.build</groupId>
<artifactId>gradle</artifactId>
<version>8.0.0-alpha06</version>
</dependency>
となってますので、以下の実装アーティファクトを解決できてるのでしょう。
Group ID com.android.tools.build
Artifact ID gradle
Version 8.0.0-alpha06
Gradle Groovy DSL
implementation 'com.android.tools.build:gradle:8.0.0-alpha06'
Gradle Kotlin DSL
implementation("com.android.tools.build:gradle:8.0.0-alpha06")
Last Updated Date 10/24/2022
👉 com.android.tools.build.gradle-8.0.0-alpha06 - Google's Maven Repository

よって、'com.android.tools.build:gradle' の記述は、plugin DSL では記述の必要はないのでしょう。
少し古いコードに以下のような記述が見られるのは、プラグインマーカーアーティファクトが公開される前のものだったということで納得できます。
pluginManagement {
// ...
resolutionStrategy {
eachPlugin {
if(requested.id.namespace == "com.android") {
useModule("com.android.tools.build:gradle:${requested.version}")
}
}
}
■ まとめ
最後に、AndroidStudio のプロジェクトテンプレートを利用して確認します。
例にならって、 New Project から Empty Activity を選択後、 New Module から Android Library を作成します。

以下、Gradle まわりの設定ファイル該当部分です。
// settings.gradle
pluginManagement {
repositories {
gradlePluginPortal()
google()
mavenCentral()
}
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
google()
mavenCentral()
}
include ':app'
include ':el'
// build.gradle
plugins {
id 'com.android.application' version '7.3.1' apply false
id 'com.android.library' version '7.3.1' apply false
id 'org.jetbrains.kotlin.android' version '1.7.20' apply false
// app/build.gradle
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
implementation project(path: ':el')
// el/build.gradle
plugins {
id 'com.android.library'
id 'org.jetbrains.kotlin.android'
'com.android.tools.build:gradle' は見当たりませんね!
素晴らしいです、Plugin DSL !!
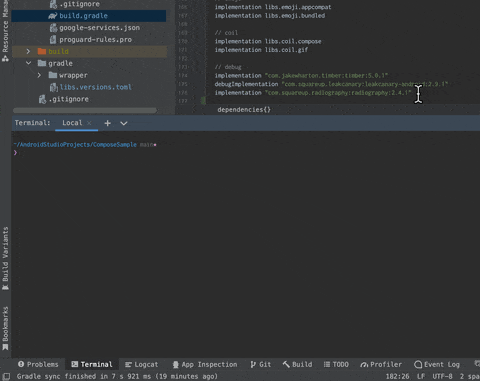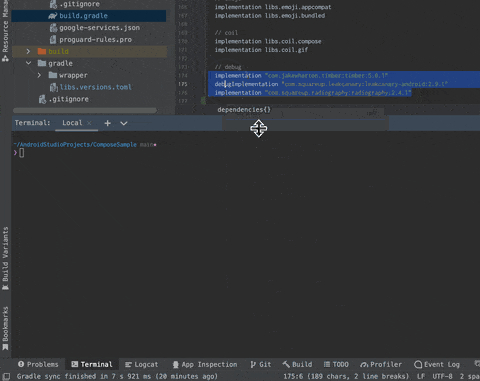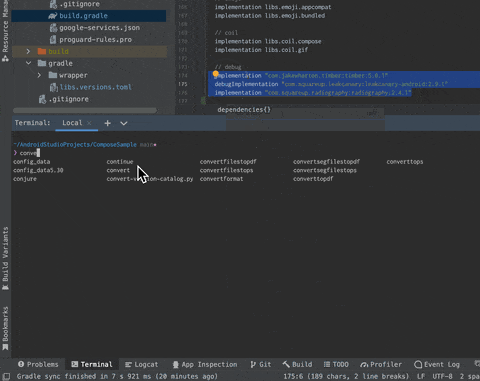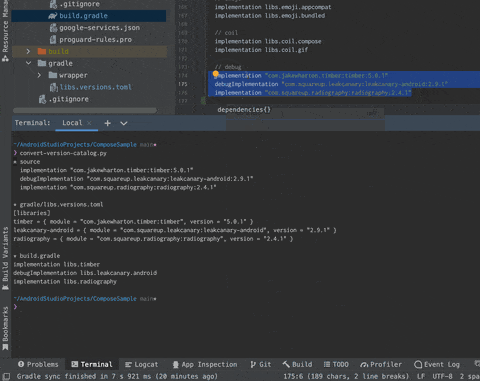
👉 Jetpack Compose Samples でも使われている「Version catalog update plugin」で libs.versions.toml を書き出してみる
👉 今現在 AndroidStudio が推してくる Gradle の設定記述と構成を2年前と比較 - libs.versions.toml, settings.gradle, build.gradle











)