「分かれば簡単だけど、分かるまで難しい」
そんなこと多いですよね。
なにを悩んでいたのか。というやつ。
SQLDelight は、1.0 となり、今現在、ドキュメントやリファレンスが少なくてはまります。
おおまかに「しくみ」を捉えてからやってみること大事です。
1.テーブル作成
テーブルを作成したい場合。SQLで、
CREATE TABLE player (
id INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
number INTEGER NOT NULL,
name TEXT NOT NULL,
time TEXT DEFAULT (strftime('%s', 'now')),
UNIQUE (number, name)
);
のようなものを書きますよね。
これは、Player.sq というファイルに書いて、所定の位置に置きます。
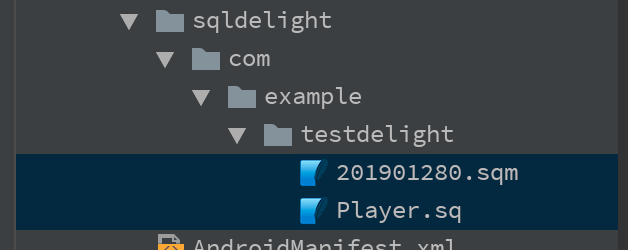
この位置はデフォルトでは、パッケージ名 com.example.testdelight の場合、
/app/src/main/sqldelight/com/example/testdelight/Player.sq
となります。
2.クエリー作成
プログラムコード上で利用したい「メソッド名」と、それに対するSQLを箇条書きにします。
selectAll:
SELECT *
FROM player;
insert:
INSERT INTO player(number, name)
VALUES (?, ?);
changes:
SELECT changes();
count:
SELECT COUNT(id)
FROM player;
これも、前述の Player.sq ファイルに追記します。

これで、テーブル周りの設定は終わりです。
3.スキーマのバージョン
ここが少し分かりづらかったのですが、
「201901281」を新バージョンにしたい場合、
「1を引いたもの」をファイル名として、
「201901280.sqm」
として置きます。
今回は、テーブル定義の変更はないので、中身なしの空ファイルです。
少し不思議な感じがしますが、書き出してみると分かってきます。
なお、このファイルを設定しなければ、適用されるバージョンは「1」となります。
4.ビルドして書き出す
ここでビルドすると、以下のようなファイルが書き出されます。

それぞれ以下のコードとなっています。



これらを使って、コードを書いていきます。
まとめ
既存の .db ファイルに対して、バージョン更新を行いたい場合のキモとなるのは、書き出される Database ファイル。
object Schema : SqlDriver.Schema {
override val version: Int
get() = 201901281 // 201801280 + 1
// ...
override fun migrate(
driver: SqlDriver,
oldVersion: Int,
newVersion: Int
) {
if (oldVersion <= 201901280 && newVersion > 201901280) { // same .sqm file name
// from 201801280.sqm contents
// ...
}
}
}
.sqm のファイル名の数字が、
「新バージョンの数字」
「適用される既存.db のバージョンの数字」
を決める。
SQLDelight 1.0 使い方 #1
SQLDelight 1.0 使い方 #2
SQLiteのユーザバージョンを利用する - Basic
Pragma statements supported by SQLite















